
Os modelos de linguagem sonham com ovelhas eletrônicas? Parte 2

16 de may. de 2025 — Juan Ruocco 🧙♂️

En general, todo lo que sea conteúdo publicitário em redes sociais é uma absoluta porcaria. Mas o outro dia me cruzei com um tweet patrocinado que me chamou a atenção. Era uma explicação bastante básica acerca do funcionamento dos Modelos Extensos de Linguagem ou Large Language Models (LLM), conhecidos sob o genérico de "Inteligência Artificial", e sobre o debate acerca da "consciência". Ou seja, se aquilo que os modelos fazem pode ser considerado "pensamento".
Nesse sentido, já tínhamos feito uma primeira aproximação acerca do que isso implica para a filosofia da linguagem e como pode ser equiparado às arquiteturas do mental, tais como o funcionalismo de máquina. Mas o tempo passou, os modelos evoluíram e também nosso próprio entendimento sobre eles.
Linguagens, máquinas e mundos
Basicamente, um dos problemas contemporâneos acerca de o que é a mente ou o mental, na filosofia da mente, está em se é possível conceber a mente como algo análogo a uma "máquina de pensar". Essa ideia, em sua fase originária, devemos à introdução da "máquina de Turing", com a qual o matemático, criptógrafo e filósofo Alan Turing descreve o funcionamento teórico/rudimentar do que hoje conhecemos como "computador". Isso disparou um montão de reflexões acerca de se a mente e seu principal produto, a linguagem, podem se entender como uma instância de uma máquina de Turing.
Todavía hay gente discutiendo si las LLMs tienen conciencia. Me da la sensación de que quienes creen eso nunca se tomaron el trabajo de entender cómo funciona una.
— Fede Caccia (@fedeecaccia) May 12, 2025
Lo básico: las LLMs no "entienden" nada.
Ajustan parámetros para minimizar una resta entre dos vectores… pic.twitter.com/6zFVMXXfBB
Mas revisando o que propunha o tweet patrocinado percebi que havia toda outra literatura em linha com isso, que se referia a outros conceitos ao redor das duas categorias fundamentais de mente-linguagem. Não é casual que muitos dos autores-chave da filosofia da mente sejam também referentes importantes da filosofia da linguagem. O que é a mente se não uma máquina de criar linguagem? Tendo isso em conta, também nos podemos perguntar então qual é a relação entre ambos conceitos.
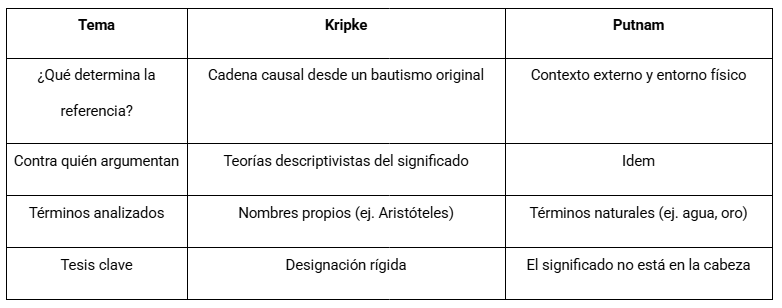
As contribuições de Hilary Putnam
O autor central ao qual vamos seguir neste artigo é Hilary Putnam, ao qual se lhe atribui a primeira formulação –ou ao menos a mais concreta– do que conhecíamos como funcionalismo de máquina. Mas, além disso, Putnam tem uma série de artigos nos quais tenta desmontar uma galeria de argumentos céticos em torno da linguagem e sua relação referencial com o mundo.
O argumento de Putnam é simples e de alguma forma está relacionado à hipótese dos macacos com máquinas de escrever. O filósofo e matemático estadunidense coloca como exemplo um grupo de formigas na praia, que se põem a caminhar traçando sulcos e –por uma questão do acaso, ou melhor dito estatística– terminam desenhando o rosto de Winston Churchill na areia. Podemos dizer que as formigas sabem desenhar? É o mesmo com os macacos com máquinas de escrever. Com suficientes macacos e suficientes máquinas, tecladas sistematicamente durante X tempo, os macacos eventualmente digitam uma cópia de Sonho de uma Noite de Verão, de William Shakespeare. Os macacos sabem escrever?
O que sabemos é que, produto de um acaso estatístico, tanto os macacos como as formigas criam algo que tem significado para os humanos que o vemos. Um modelo de linguagem extenso é como os macacos e as formigas mas otimizado por quase um século de informática, matemática e indústria de semicondutores.
A partir desse breve momento de lucidez, decidi voltar a conversar com o modelo GPT (agora em sua versão 4) e fazer um breve resumo desse caminho sobre o externalismo semântico, o funcionamento dos modelos de linguagem, o sentido e a referência. Tudo o que há a seguir são as respostas ou conclusões do GPT-4 de Open AI.
Putnam e a Terra Gêmea
Em Hilary Putnam, o externalismo semântico é uma teoria filosófica que sustenta que o significado das palavras não depende só do que ocorre na mente do falante, mas também do ambiente externo. Como diz sua famosa frase: "O significado não está na cabeça".
Em 1975, o filósofo, matemático e informático teórico estadunidense desenvolveu um famoso experimento mental, o da Terra Gêmea, que propõe imaginar dois planetas idênticos: a Terra e a Terra Gêmea. Em ambos há pessoas que usam a palavra "água". Na Terra, refere-se a H₂O. Na Terra Gêmea, a um líquido indistinguível da água, cuja composição química é XYZ. A conclusão de Putnam é que, embora os falantes em ambos mundos tenham os mesmos estados mentais ao pensar em "água", a palavra refere a coisas distintas, porque a substância no ambiente é diferente.
Quais são as implicações disso? Que o conteúdo mental não determina por si só o significado de nossas palavras; e que a intenção subjetiva do falante é insuficiente para fixar o significado sem a contribuição do contexto físico e social.

Saul Kripke e os nomes próprios
A conexão entre Putnam e Saul Kripke é fundamental para entender o giro externalista na filosofia da linguagem dos anos 70. Em Naming and Necessity (1972), Kripke critica a teoria descritiva do significado (Frege/Russell), propondo que:
- os nomes próprios não significam uma descrição;
- em vez disso, são designadores rígidos que referem ao mesmo objeto em todos os mundos possíveis.
Por exemplo, "Aristóteles" não significa "o mestre de Alexandre" ou "o autor de Metafísica" mas simplesmente esse cara, fixado historicamente num batismo original.
Putnam e os termos naturais
Putnam retoma essa ideia de referência direta e a estende a termos naturais como água, ouro, tigre. Segundo ele:
- não referimos por uma descrição interna (ex. "líquido incolor"), mas por uma relação causal com o mundo e a comunidade linguística;
- por isso, embora não saibamos a composição química de "água", o termo refere a H₂O se essa é a substância em nosso ambiente.
Convergências entre Putnam e Kripke
Ambos defendem uma teoria causal-externalista da referência, embora Kripke se enfoque em nomes próprios e Putnam em termos gerais ou naturais.
Terra 2
A pergunta de como os modelos de linguagem (LLM) podem gerar linguagem com sentido sem "saber" o que estão fazendo dialoga diretamente com o externalismo semântico de Putnam e as contribuições de Kripke.
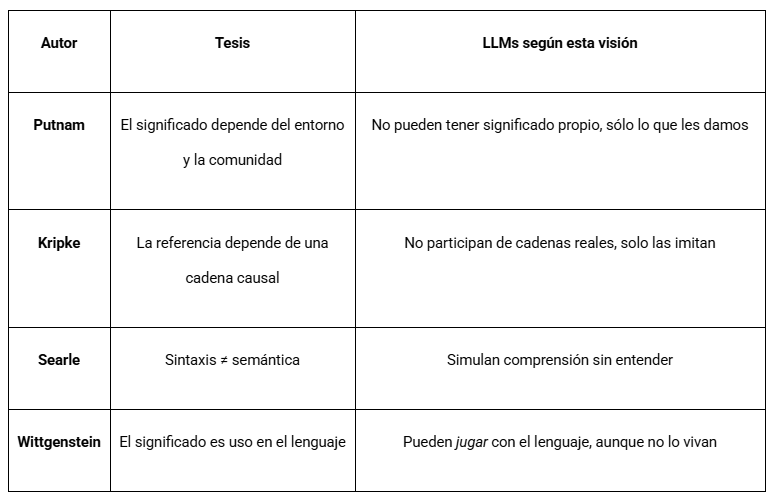
O que diria Putnam dos LLM?
Putnam sustenta que o significado não se reduz a estados internos (nem mentais, nem sintáticos), mas que requer um ambiente externo (químico, social, histórico), uma conexão causal com as coisas do mundo, e uma comunidade linguística que dá sentido e referência às palavras. Um LLM não tem acesso ao mundo nem participa de uma comunidade intencional. Por isso, segundo o externalismo clássico, não tem intencionalidade genuína: não refere, não significa no sentido forte. Apenas simula significado ao gerar sequências coerentes segundo estatística e contexto.
Analogia com a Terra Gêmea
O LLM seria como um falante numa Terra Gêmea que diz "água" sem ter interagido com H₂O ou XYZ. Diz "água" porque assim está em seus dados, mas não sabe (nem pode saber) a que refere. Isso revela o ponto-chave: os LLM podem produzir linguagem significativa para nós, mas não para eles.
Kripke e a falta de referência real
Para Kripke, referir exige uma cadeia causal histórica. Um LLM não participa dessa cadeia. Se diz "Napoleão", o faz por padrões estatísticos, não porque alguma vez tenha havido um batismo referencial. Seu uso do nome é parasitário do nosso.
Então, os LLM não entendem nada?
Depende do que entendamos por "entender". Desde o externalismo semântico forte: não, não entendem nada. Mas desde uma visão mais funcionalista ou pragmática: entendem o suficiente como para operar em um ambiente comunicativo com humanos. Nesse sentido, poderíamos dizer que um LLM "faz de conta que entende", mas o que produz só tem significado porque o interpretamos nós, ancorados em nossas práticas, hist��ria e mundo.
Os LLMs são Terra Gêmea: geram signos sem história, sem ambiente físico, sem intenção. Mas os humanos os interpretamos desde nosso mundo, dando-lhes nosso significado. O que para eles é ruído estruturado, para nós é linguagem.

Searle e a Sala Chinesa
O filósofo americano da mente e da linguagem John Searle apresenta uma crítica direta à ideia de que simular compreensão equivale a entender. Em 1980, ele realizou seu famoso experimento da Sala Chinesa.
- Você está em uma sala fechada (a "sala chinesa").
- Você recebe perguntas em chinês por debaixo da porta.
- Você não sabe chinês, mas tem um manual em português que te diz exatamente quais símbolos devolver para cada conjunto de símbolos que entram.
- De fora, os chineses pensam que você entende o idioma porque suas respostas fazem sentido.
A tese de Searle
Embora o sistema pareça entender chinês, ninguém dentro do sistema realmente entende. A manipulação sintática não produz semântica e, portanto, um computador que processa símbolos não tem compreensão nem consciência.
Aplicado a LLMs, um modelo de linguagem funciona como a sala chinesa. Não sabe o que diz, apenas aplica regras estatísticas para gerar o que soa adequado. O "significado" só ocorre quando alguém lê e interpreta.
Wittgenstein: significado como uso
Ludwig Josef Johann Wittgenstein segue outro caminho. O filósofo, matemático e linguista austríaco não busca uma essência do significado, mas observa como usamos a linguagem na vida cotidiana. Ele enfatiza, de fato, que "o significado de uma palavra é seu uso na linguagem".
- Não há uma "tradução interna" mágica da linguagem para o pensamento.
- O importante é a prática, o jogo de linguagem.
- A linguagem é entendida dentro de uma trama social, repleta de regras, hábitos, contextos.
Aplicado a LLMs, embora um LLM não tenha intenções nem consciência, ele participa de jogos de linguagem no sentido pragmático, gerando textos que podem ser utilizados, respondidos, refutados, incorporados. Nesse sentido, gera significado funcional, embora não intencional.
Em resumo, Putnam/Kripke focam em referência e realismo semântico; Searle foca em intencionalidade e consciência; e Wittgenstein foca em uso cotidiano e forma de vida.
A ética requer agência intencional
Na maioria das tradições éticas (kantiana, utilitarista, aristotélica), parte-se do pressuposto de que:
- um agente entende o que faz,
- pode deliberar sobre o bem ou o mal,
- e tem um propósito ou uma vontade.
Os LLMs não cumprem nada disso: não têm consciência, compreensão semântica, interesse próprio nem capacidade para justificar seus atos. Dessa perspectiva, não podem ser agentes morais nem sujeitos éticos. São instrumentos.
No entanto, a responsabilidade não desaparece. Apenas se desloca. Há pelo menos três níveis:
• Responsabilidade do programador/desenvolvedor (quais dados foram usados, quais limites o modelo tem, como o viés, a toxicidade e a filtragem são configurados)
• Responsabilidade do usuário (como é usado, se é usado para manipular, usurpar ou desinformar)
• Responsabilidade do ecossistema (quais normas são construídas em torno dessas tecnologias, que grau de autonomia se permite em ambientes críticos)

E se o modelo se tornar autônomo?
Se imaginarmos um futuro onde um sistema aprende a longo prazo, interage com o mundo real, forma intenções emergentes (simuladas ou não) e se integra socialmente, então alguns filósofos (como Floridi ou Gunkel) argumentam que deveríamos considerar certo status moral a essas entidades, pelo menos como pacientes morais (não agentes, mas objetos de cuidado ou regulação).
Conclusão ética desde a perspectiva atual
Atualmente, um LLM:
- não é um agente moral,
- não pode ter culpa nem mérito,
- e o "significado" de suas respostas é projetado pelo usuário e pela comunidade humana.
Como disse Searle: "Um computador pode parecer entender a linguagem, mas não tem nem crenças nem desejos". Mas você tem, e por isso a ética está em como você decide usar os LLMs.