¿Te atrae la IA pero no querés que tus datos viajen a servidores corporativos? Descubrí cómo correr modelos de lenguaje de forma 100% local, privada y "off-grid" en tu propia computadora, usando hardware hogareño y herramientas open-source. El futuro de la IA no se hostea en la nube.
Un paso natural luego de leer la nota que publiqué el mes pasado es pensar en correr modelos de lenguaje localmente. Quizás te atrae la idea de usar modelos de lenguaje, pero no te gusta mucho la idea de que tus flujos de trabajo vayan y vuelvan a un centro de cómputo de una empresa proveedora del Departamento de Defensa estadounidense, o simplemente no querés que pasen por ninguna empresa, te gusta mantenerte fuera del radar (off-grid, como quien dice). En esta nota me propongo darte una idea de lo que podrías lograr y lo que te costaría hacerlo. Incluso si todavía no podés correr modelos particularmente buenos, probablemente te sirva para mantenerte atento. Es muy posible que usar lo que hoy se considera un modelo de frontera se vuelva asequible en no tanto tiempo.
Hoy quiero hablar de lo que se puede hacer con bastante poco por gente como yo que somos tecno-hobbyístas, no laburamos de esto. Muchas de las cosas que voy a mostrar le van a dar escalofríos a gente que sabe de computadoras, les va a parecer crudo, básico, temerario incluso. Pero este crimen contra las buenas prácticas informáticas y la inteligencia es un crimen sin víctimas, como si me hiciera un tatuaje feo. Pueden tomarlo simplemente como una crónica de intentar hacer andar modelos locales por parte de un incauto docente de humanidades. Qué se le va a hacer, yo aprendo así. En inglés existe el dicho: An ounce of practice is generally worth more than a ton of theory (un gramo de práctica vale más que una tonelada de teoría), los calabreses: A pratica ruppi a grammatica (la práctica rompe a la gramática [las reglas]), y nosotros tenemos varias de esas. A mí me gusta el pragmatismo en filosofía (que, a diferencia de en otros ámbitos, no implica sociopatía), así que para mí van de la mano.
"Buena máquina, pero ¿corre el Crysis?" 2.0
¿Te acordás de cuando tener una placa de video salía un huevo? Bueno, siempre fue así, ¿pero te acordás cuando los más manijas tenían dos? Quizás eras de esos, quizás eras de los que se ponía a minar cripto y con eso se compró un rig para hacerle saltar la térmica a la vieja. Bueno, ser de esos hoy es tener el hard necesario para correr modelos locales que sirvan para algo más o menos útil, más o menos groso.
Hay buenas razones para pensar que el futuro de los modelos de lenguaje, en gran medida, va a ser una cuestión de modelos de lenguaje locales, que corran en tu computadora o servidor hogareño.
En algún sentido por ahora es para entusiastas y profesionales de Machine Learning, pero pronto podría dejar de ser así. Hay buenas razones para pensar que el futuro de los modelos de lenguaje, en gran medida, va a ser una cuestión de modelos de lenguaje locales, que corran en tu computadora o servidor hogareño. Lo mismo para muchas empresas. Empresas que manejen datos sensibles no pueden darse el lujo de tener sus datos hosteados en cualquier lado, tampoco van a poder tenerlo procesados en cualquier lado. Así como la revolución no será televisada, tampoco será hosteada en la nube o procesada en datacenters en Texas.
¿Qué implica correr un modelo local?
Un modelo de lenguaje generativo tiene un ciclo triádico como muchas cosas que hacemos los humanos: entrenamiento, post-entrenamiento e inferencia. Todo se hace en datacenters, pero mientras que el entrenamiento de un modelo de lenguaje actual es prohibitivo para casi todo el mundo que no sean los grandes laboratorios de IA de EEUU (Google, OpenAI, xAI, Anthropic y Meta) y China (Deepseek, Qwen, Kimi, etc.), más los franceses (Mistral), y el post-entrenamiento es desde imposible para amateurs a algo costoso, la inferencia tiene costos operativos mucho menores. Inferencia es cómo los especialistas llaman al cómputo que hace un modelo de lenguaje. En definitiva es el cómputo operativo cuando el modelo está corriendo, a diferencia de cuando está siendo entrenado o tuneado.
Lo requerido para ofrecer inferencia depende de varias variables, el tipo de chips sobre los que se ejecuta el modelo ya entrenado, la cantidad de ram disponible (preferiblemente VRAM, la que tienen las placas de video, ya que lo mejor para correr estos modelos en una computadora no industrial es una GPU) y los drivers (y soft) disponibles.
Para quienes tienen una placa de video NVIDIA RTX 2xxx en adelante (especialmente, si terminan en 70 o más) la forma más fácil de probar es bajarse algo como ollama o vllm. Una RTX 2070 te alcanza para probar; para trabajar cómodo conviene arrancar de una RTX 3060 de 12 GB en adelante. Ollama es una forma bastante amigable para principiantes para correr modelos locales, ofrecen una gran cantidad de modelos y es fácil encontrar información sobre qué hardware hace falta. Mientras más nueva sea tu placa de video, más vas a poder correr. El caso ideal es tener una RTX 5090 con un micro bueno, buena ram y SSDs (una máquina de 9-16 palos en precios locales, o de 5 o 10 mil dólares o más si comprás y traés de afuera). Ahí vas a poder correr tanto como pueda correr alguien no especialista y particular. Una placa de video industrial de las mejores está arriba de 30 mil dólares, los datacenters de IA tienen decenas de miles, en Argentina creo que no hay ni una. Es decir, no estamos hablando de eso. Estamos hablando de atar lo que se pueda con alambre.
Desde ya, podés ir más lejos, podés armarte un rig más heavy, más en camino a tener un servidor de IA en tu casa. Pero salvo que tengas mucha plata o estés intentando armar una empresa, esto es demasiado para chusmear. También podés hacer lo que hicieron muchos: comprarte Mac Minis para armarte un server hogareño como hicieron durante la fiebre de ClawBot muchas personas (de credibilidad que no me atrevo a calificar) el verano que pasó, tanto que el precio de las Mac Mini más básicas subió 200 dólares hace unos días (de ~500 dólares a ~700).
No soy gamer, laburo. Hablame de notebooks
Lo interesante de los modelos locales es que dentro de poco probablemente lo más sensato sea correrlos en hardware que está igual de disponible para escritorio como para notebooks. La gran diferencia está dada por los micros ARM (como los M de Apple y los nuevos Snapdragon) y módulos integrados para optimizar inferencia en micros Intel y AMD. No está claro para dónde va todo esto (si va a ser un nuevo estándar), pero ya hay modelos disponibles.
Si estás en búsqueda de cambiar hardware, podés tomar esto en cuenta antes de comprar. Por ejemplo, suponete que sos un diseñador y solés comprar MacBooks Pro. Quizás quieras romper el chanchito y comprarte la mejor posible: el mejor micro M5 con la mayor cantidad de ram que le puedas poner (128 gb, si no me equivoco). No vas a tener tanta rapidez como con una RTX 5090, pero vas a poder correr más modelos. Algunos van a estar a la altura de un Claude Sonnet 4.5 para muchas tareas. Básicamente, te independizaste de subscripciones. Eso sí, en vez de gastar 20, 100 o 200 dólares mensuales, estás gatillando 5000 de una. Quizás usás alguna suscripción, pero podrías ahorrar tokens o directamente evitar muchas tareas reorientándolas a modelos locales.
Si no usás Mac, podés optar por una computadora con Windows que utilice los nuevos micros AMD o Intel con "cores" designados como NPUs (Neural Processing Units) que gastan menos electricidad y no son placas de video. Son hardware hecho para procesamiento de redes neuronales (modelos entrenados). También están saliendo computadoras para Windows y Linux con micros ARM (es decir, no son arquitectura x86, si esto te significa algo) pero Snapdragon. Ultra eficientes, memoria compartida entre tareas gráficas y "normales".
No voy a dejar de usar suscripciones, ¿para qué me sirve?
Si usás cosas como Claude Code u otros servicios de LLM por línea de comando, podés hacer que esos modelos usen modelos locales para exportar trabajos. Por ejemplo, si pudieras correr un modelo que sea bueno resumiendo, puede hacerle de mulo a tu Claude para ahorrar tokens. En vez de leer el archivo entero, Claude lee el resumen hecho por tu modelo local.
Usos típicos de modelos locales
Modelos sin censura. Imaginate que sos un GM de un juego de rol medio zarpado; por lo que me enteré, hay un mercado inmenso de modelos de lenguaje orientados a freaks, roleros y gente que quizás no quiere lidiar con filtros de contenido para armar historias o armar juegos. Lo mismo aplica para escritura de ficción adulta, exploración de temas oscuros con fines de investigación, o simplemente para no toparte con un "no puedo ayudarte con eso" cuando le pedís a un agente que te asista a redactar un dictamen judicial sobre un crimen violento.
Autocompletar para programar. Suponete que usás Visual Studio Code, el autocomplete lo hace copilot. Podés configurarlo para que de eso se ocupe un modelo tipo Qwen 9b. Por lo que anduve viendo (esto yo no lo uso), plugins como Continue.dev o Twinny te dejan apuntar al servidor local (ollama, llama.cpp, vllm) y olvidarte de la suscripción a Copilot. Para autocompletar variables, escribir tests sencillos o documentar funciones, un modelo de 7-14b cuantizado es suficiente.
Bucles de automatización de tareas. Podés hacer que todos los días a las 10 de la mañana un modelo local lea tus mails, los resuma y los jerarquice. Si te tomás el trabajo de ir tuneando esta forma de trabajo, te puede servir. No hay que pedirles que razonen mucho, sino tareas acotadas y repetibles: clasificar, extraer nombres, traducir, formatear.
Resumen y producción de texto. Es uno de los usos donde los modelos chicos brillan más: tienen menos contexto y menos "creatividad" que un Sonnet o un Opus, pero para tareas básicas de texto o extraer información de un .pdf pueden llegar a ser más que suficientes.
Manejo de datos sensibles o por los que podrías ir preso de sacar de tu computadora. Si tu trabajo involucra datos médicos, judiciales, financieros o de clientes bajo contratos de no divulgación o cosas así, mandar cualquiera de esas cosas a un proveedor en la nube puede ser literalmente ilegal según la jurisdicción. Un modelo local te deja hacer el mismo flujo (resumir historias clínicas, redactar borradores de demandas, anonimizar entrevistas) sin que un solo token salga de tu máquina. Desde ya, se va a romper la ilusión de que una máquina perfecta y neutral hace un trabajo mejor del que podrías hacer vos. Al igual que si le delegaras ese trabajo a ChatGPT, tenés que revisarlo concienzudamente. No hacen magia.
Va un ejemplo
Tengo una placa de video Radeon RX 6700 XT. Es decir, una placa AMD. NVIDIA tiene el monopolio virtual de las placas de video de gaming y las orientadas a trabajo con IA porque no sólo desarrolla buen hardware, sino que tiene los mejores drivers y software para usarlos. Hoy en día ser programador en CUDA (el lenguaje para utilizar CUDA-cores de NVIDIA) debe ser uno de los rubros más rentables y codiciados del ámbito de la programación, y un parto. Pero es mejor que la alternativa. En cambio AMD viene apostando hace mucho a drivers open source que son notoriamente inferiores a los de NVIDIA. Hoy en día tiene excelentes placas, pero no logran insertarse en el mercado exitosamente. Yo tengo una de esas, así que sería esperable que no pueda hacer gran cosa con modelos de lenguaje.
Si tu trabajo involucra datos médicos, judiciales, financieros o de clientes bajo contratos de no divulgación o cosas así, mandar cualquiera de esas cosas a un proveedor en la nube puede ser literalmente ilegal según la jurisdicción.
Los modelos de lenguaje existen gracias, en parte, a los que jugamos videojuegos. No porque gracias a los videojuegos se haya creado la idea de redes neuronales o del conexionismo en IA en general, sino porque estas ideas que tienen más de 60 años se volvieron factibles sólo gracias a la abundancia de chips de procesamiento paralelo creados para resolver el problema de cómo comunicarle a un monitor en tiempo real de qué color tenía que ser cada centímetro cuadrado de pantalla. Un procesador paralelo no se especializa en computar cosas difíciles una atrás de la otra, sino en resolver operaciones (digamos) matemáticas relativamente sencillas muy rápido y en paralelo. Eso es lo que se necesita para procesar video. Y hace aproximadamente veinte años varias personas se dieron cuenta de que estas mismas cosas servían para simular (o correr) redes neuronales (sin ir más lejos, el fundador de DeepMind, ahora de Google, arrancó su carrera haciendo videojuegos, podés ver el video más abajo). Nuestras neuronas son muy tontas cada una, pero si juntás suficientes trabajando de ciertas maneras particulares, podés tener a un Bach, un Einstein, un Gödel, un Messi, un Leloir, etc. Desde ya, también podés tener a todos los ganadores de los premios Darwin.
Se dice que Stalin (o Hegel, o no se sabe quién) dijo que la cantidad tiene una cualidad propia, y, como enjambre Zerg, las cientos de miles de operaciones sencillas pero paralelas que hacen nuestras placas de video (para, justamente, permitirnos sentir el desasosiego de un Protoss que no hizo un observer a tiempo) son las que hacen falta para que un modelo de lenguaje diga que sos una persona brillante y no valorada por todos los que te conocen (como quizás le pasó recientemente al famoso biólogo Richard Dawkins), o, quizás de forma más útil, para hacerte una página web. El misterio de los modelos de lenguaje es que no hay misterio alguno en las operaciones que hacen, pero hacen tantas que encontrar patrones inteligibles en su operación es todo un desafío de ingeniería inversa apenas menor (en un sentido de "apenas" y otro de "menor") al de comprender lo que pasa en nuestro cerebro cuando elegimos gustos de helado.
Todo esto es para decir que mi placa no es NVIDIA, que no debería poder correr nada útil; pero me puse el desafío charlando con Juan como disparador de esta nota, e inclusive yo, que tengo una placa de video equivalente a la de una Playstation 5 (esto no es mucho decir hoy en día), puedo hacer algo que me sirve. Ah, me olvidé de decirles, el modelo de mi placa no está soportado por AMD para correr sus drivers especializados de IA; pero ni siquiera eso me detuvo (gracias a la ayuda de modelos de lenguaje y la poca preocupación por la autopreservación de mi computadora mediante). Entonces, mi argumento es el siguiente: si incluso mi placa de video sirve para hacer algo, seguro muchos de ustedes también pueden hacer algo (probablemente mejor) con las suyas, ahora o en el futuro.
Esto tiene que ver con una tendencia bastante molesta, ¿por qué los precios de la RAM y las placas de video se fueron por las nubes? Porque los modelos de lenguaje necesitan tener una gran cantidad de sus neuronas cargadas en memoria para ejecutarse, y si las GPU corren mejor los cómputos que requieren las redes neuronales, la memoria que importa es la de las placas de video. La VRAM. Esa que para nosotros los millenials era un falso sinónimo de la potencia de una placa de video. Decir que tenías una placa de 512 MB de VRAM era una locura, pero era sólo correlación y no exactamente causa. Necesitás más VRAM en una placa de video sólo en la medida que los archivos de texturas sean más grandes, y cuando a nadie le importó mucho empezar a jugar en 4k la VRAM dejó de ser relevante. La enorme mayoría juega en 1080p, así que con 10 GB de VRAM estamos sobrados. Pero los modelos de lenguaje no.
Las GPU son muy rápidas procesando redes neuronales, pero son tan buenas que luego termina importando bastante más cuánta VRAM tenés para alimentarles más cuentitas tontas para masticar. Tu GPU puede hacer muchas en serio, así que mientras más VRAM, más parámetros puede tener el modelo de lenguaje que corrés. Al mismo tiempo, hay una correlación muy grande entre los parámetros de un modelo de lenguaje y sus capacidades (que con colegas intentamos ayudar a medir, tema para otro día) – pero ojo, de la misma manera que pensar que una placa de video con más VRAM es mejor resultó una falacia, considerar que un modelo de lenguaje con más parámetros es automáticamente mejor también (un modelo como los últimos y mejores de OpenAI o Anthropic tiene en el orden de Trillions [en inglés] y billones [en castellano]), la carrera que se viene es ver qué tan chicos pueden ser manteniendo la funcionalidad de modelos más grandes.
Este tipo está corriendo un Qwen 3.5 35B en un avión sin conectarse a un servidor. Lo está usando con Pi, un equivalente a Claude Code open source que te permite conectar cualquier modelo.
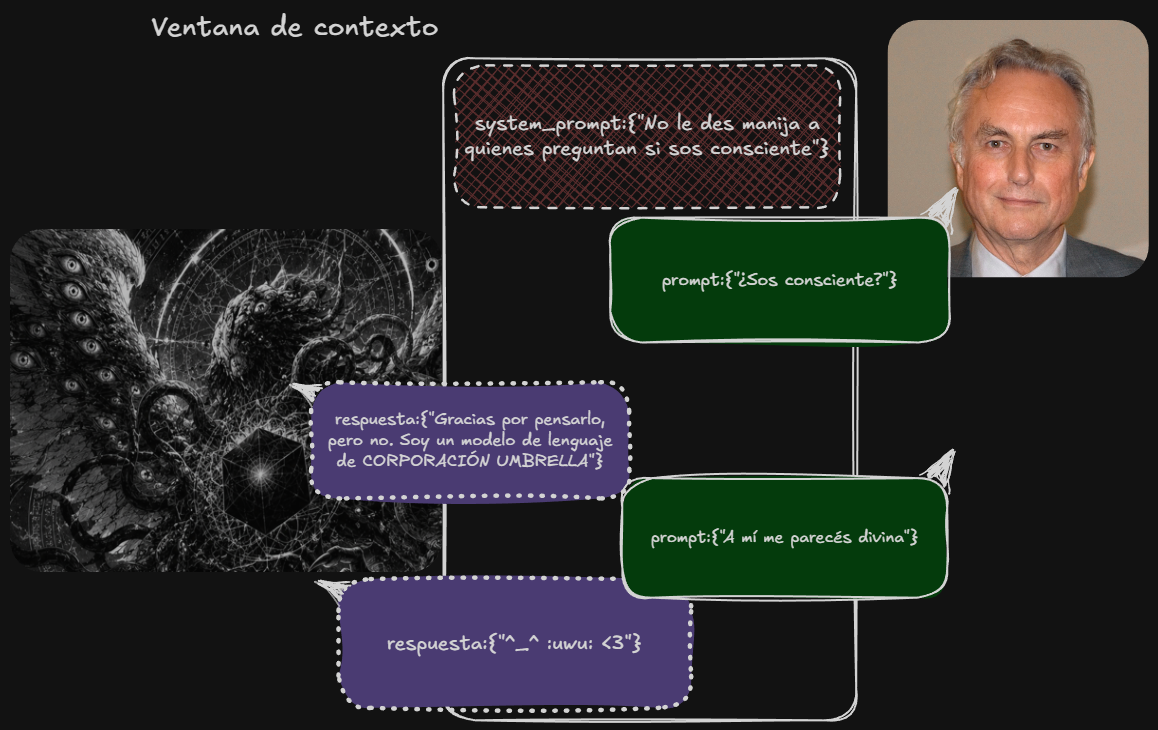
Esto quiere decir que (para hacer cosas pesadas tipo programar o buenas en general) necesitás correr modelos con bastantes parámetros; el piso para hacer cosas como programar, por ahora, es alrededor de 20b. Eso requiere mínimo 16-20 GB de VRAM. Porque además no alcanza con cargar los pesos (básicamente, los valores de las neuronitas digitales) en la VRAM y que estén esperando cual minion de Gru para hacer algo con los tokens que les tires; además necesitás espacio para la ventana de contexto. Como veremos más abajo, no todo en la vida es programar y se puede hacer bastante con menos. La ventana de contexto de un modelo es lo que el modelo ve, eso incluye las instrucciones que tiene tu modelo de su fabricante (el system prompt) y lo setea para cumplir un rol (como "sos un asistente de inteligencia artificial copado que piensa que el usuario no es un idiota"), los prompts que le das vos, y lo que el mismo bicho te responde haciendo cientos de miles de multiplicaciones de matrices para decidir cómo continuar la ventana de contexto (sus compleciones o predicciones). Todo eso tiene que estar en memoria, y algunos modelos pueden tener un límite de ventana de contexto de n, pero si la memoria de dónde corren (en este caso mi máquina) no se lo banca, bueno, tenés menos. Lo que no está en la ventana de contexto no existe para el modelo, se va borrando. Y a medida de que se va llenando funcionan peor. Por eso, modelos como Gemini 3.1 se ufanan de tener un millón de tokens de ventana de contexto, así como el modelo Opus 4.7 que podés usar con la versión Max de Claude.
Un modelo (aquí simbolizado como una entidad lovecraftiana) computa lo que "ve" en su ventana de contexto. El system prompt determina qué rol va a jugar, en general se les dice "hacé de cuenta que sos un asistente de IA servicial". Buena parte de lo que dice se basa en toda la ficción sobre agentes de IA que tiene en sus datos de entrenamiento. Preguntarle si es consciente es tan útil como preguntarle si es Aragorn.
Un agente al que le podés dictar notas
En mi exploración para esta nota, llegué a una receta jugando con Claude y Codex bastante sencilla. El código completo, con README e instrucciones de instalación, vive en github.com/msantelli/bichito-421. No hace ni falta aclarar que la instalación va a riesgo de cada quien, los cybercirujas no lloran. Los ingredientes son estos:
llama.cpp /Para correr un modelo Qwen3 de 8b cuantizado (pensá comprimido) por los capos de Unsloth
FFmpeg /Soft open-source para grabar el audio directo de tu micrófono
Python 3.11 /Para pegar todo en los scripts
Windows PowerToys /Para hacer un atajo de teclado que ejecute todo esto. Porque además lo estoy haciendo en Windows, todavía no pude dar el salto a usar sólo Linux, claramente la plataforma ideal para jugar con estas cosas.
Ahora en español: llama.cpp es un paquete open source hecho en C/C++ para correr modelos de lenguaje localmente. Nació del (fallido) proyecto Llama de Meta, pero por ahora viene siendo de los paquetes más versátiles para correr modelitos (para una versión lista para jugar podés probar ollama, que usa servidores tipo llama.cpp). whisper.cpp es básicamente lo mismo que llama.cpp, pero adaptado a modelos voz-a-texto o texto-a-voz. Uno (llama) corre nuestro modelo de lenguaje que funciona como agente (el Qwen), y otro (whisper) nuestro modelo que le traduce a texto lo que hablamos (whisper-large-v3-turbo). FFmpeg graba audio y video, transforma audio, etc. Herramienta open-source muy versátil que se ocupa de encontrar nuestro micrófono y grabar los archivitos .wav que luego el modelito whisper transcribe y el Qwen toma. Qwen es una familia de modelos entrenados por la empresa china Alibaba. Los modelos grandes los podés correr directo de ellos en los servidores de Alibaba, pero no es la idea. La gracia es que liberan modelos que podés bajar y correr vos si te da el hardware. En este caso estamos usando uno de la línea Qwen 3 de 8 miles de millones (billion) de parámetros.
Los modelos de lenguaje una vez entrenados pueden pesar bastante (sus pesos, valga la redundancia, pesan bastante) y cargarlos en "resolución" completa, por así decirle, deja poco espacio para trabajar. Por eso estoy usando una versión de Qwen que otra gente cuantizó, es decir: comprimió (no muy distinto a redondear y truncar los valores de los pesos del modelo, en vez de que algo sea 8.333333... estos lo aproximan a 8.3). La gracia es que puedo trabajar con la VRAM que tengo.
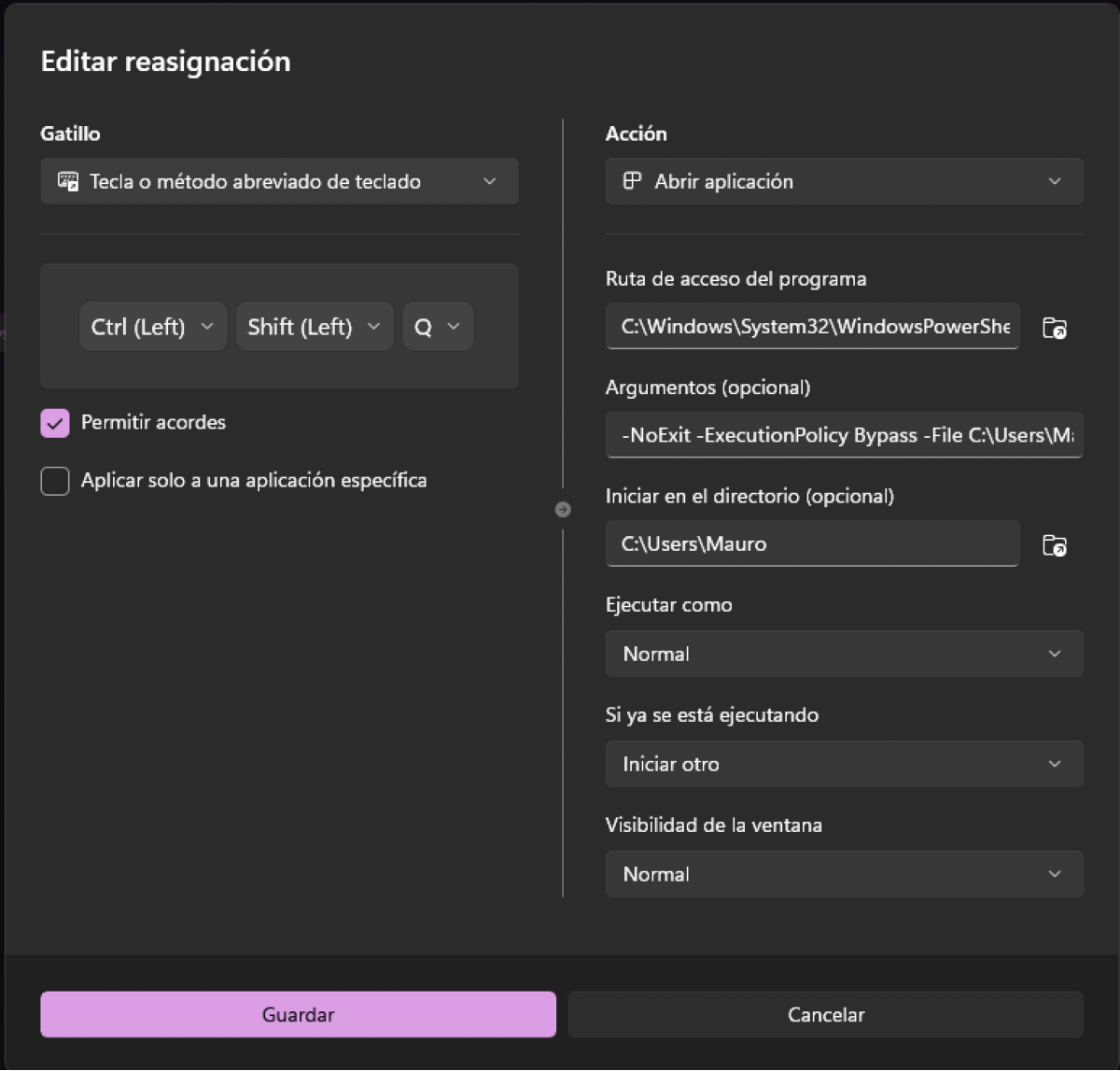
Por último, necesito Python 3.11 (porque sí), y Microsoft PowerToys, que es una serie de herramientas que Microsoft largó para manijas de la productividad para hacerte tu computadora más configurable, tipo como sería con Linux, o, a veces, con Mac. La uso para hacer un atajo de teclado que abre una consola de powershell.exe y ejecuta obsidian-agent --from-voice. Apreto Ctrl+Shift+Q, FFmpeg arranca a grabar, hablo, le doy Enter, whisper transcribe, y unos segundos después la idea quedó en el vault. Nada salió de la computadora.
Cómo funciona el agentito este
El proyecto son cuatro módulos de Python que sólo usan la librería básica, sin nada más para descargar (como he dicho, para usuarios como yo, estas preguntas mejor tirárselas a un modelo). El loop principal habla con llama-server por la API OpenAI-compatible (/v1/chat/completions) –un estándar, nada importante– y llama herramientas (tool calling): el modelo no genera markdown libre y lo escribe a un archivo, sino que elige entre un set acotado de herramientas (scripts que ejecuta) — obsidian_search, obsidian_read, obsidian_append, obsidian_daily_append, obsidian_bookmark, etc., y va decidiendo en sucesivas vueltas hasta producir una respuesta. Cada herramienta termina invocando el CLI de Obsidian (obsidian.com, que viene con la app desktop en Windows) para mirar o tocar el vault.
Lo importante de la arquitectura es lo que el agente no puede hacer. Lo que se le permite escribir es únicamente aditivo: agregar contenido al final o al principio de una nota existente, agregar a las notas diarias de Obsidian, dejar un marcador. Borrar, mover, renombrar, crear archivos nuevos, mutar las carátulas (lo que Obsidian llama frontmatter con metadatos) o ejecutar comandos arbitrarios están en una lista de mandamientos prohibidos y hardcodeada que el agente no puede saltear (o no debería). Antes de cada escritura se crea una copia de seguridad de la nota original en %LOCALAPPDATA%\obsidian-agent\backups\, se genera un archivo de auditoría en JSONL, y (salvo --yes) confirmación interactiva ante acciones polémicas (se puede setear si uno se siente más confiado). Una llamada errada del LLM puede agregar ruido al final de una nota, pero no puede perder ni distorsionar contenido.
La pregunta deja de ser "¿es posible la privacidad con los LLMs?" y pasan a ser: "¿qué tanto me interesa?", "¿cuánto cuesta?" y "¿vale la pena?". Estas son preguntas que también deberían hacerse las empresas, las universidades y el Estado antes de volverse dependientes de sistemas que se computan en la otra punta del planeta.
El modo voz (obsidian-agent --from-voice) graba con FFmpeg, transcribe con whisper.cpp, y un clasificador chico decide si la transcripción es una consulta (entra al loop del agente) o un memo (se agrega a la nota diaria de hoy con marca de tiempo). Para los detalles podés chusmear el README del repo.
El agente espera que llama-server esté corriendo en 127.0.0.1:8080. El repo de ejemplo trae un script (scripts/start-llama.ps1) que arranca con la configuración para la que tengo seteado el system prompt (las instrucciones que recibe el modelo ["sos un asistente de notas, hablás en rioplatense..."]):
Tecla Windows + X y luego i (no todo al mismo tiempo), copiar y pegar esto si lo querés hacer a mano. Este comando te descarga el modelo si no lo tenés también. Pero primero te tenés que instalar llama.cpp corriendo este otro comando winget install llama.cpp (no es nada raro, simplemente te instala llama.cpp).
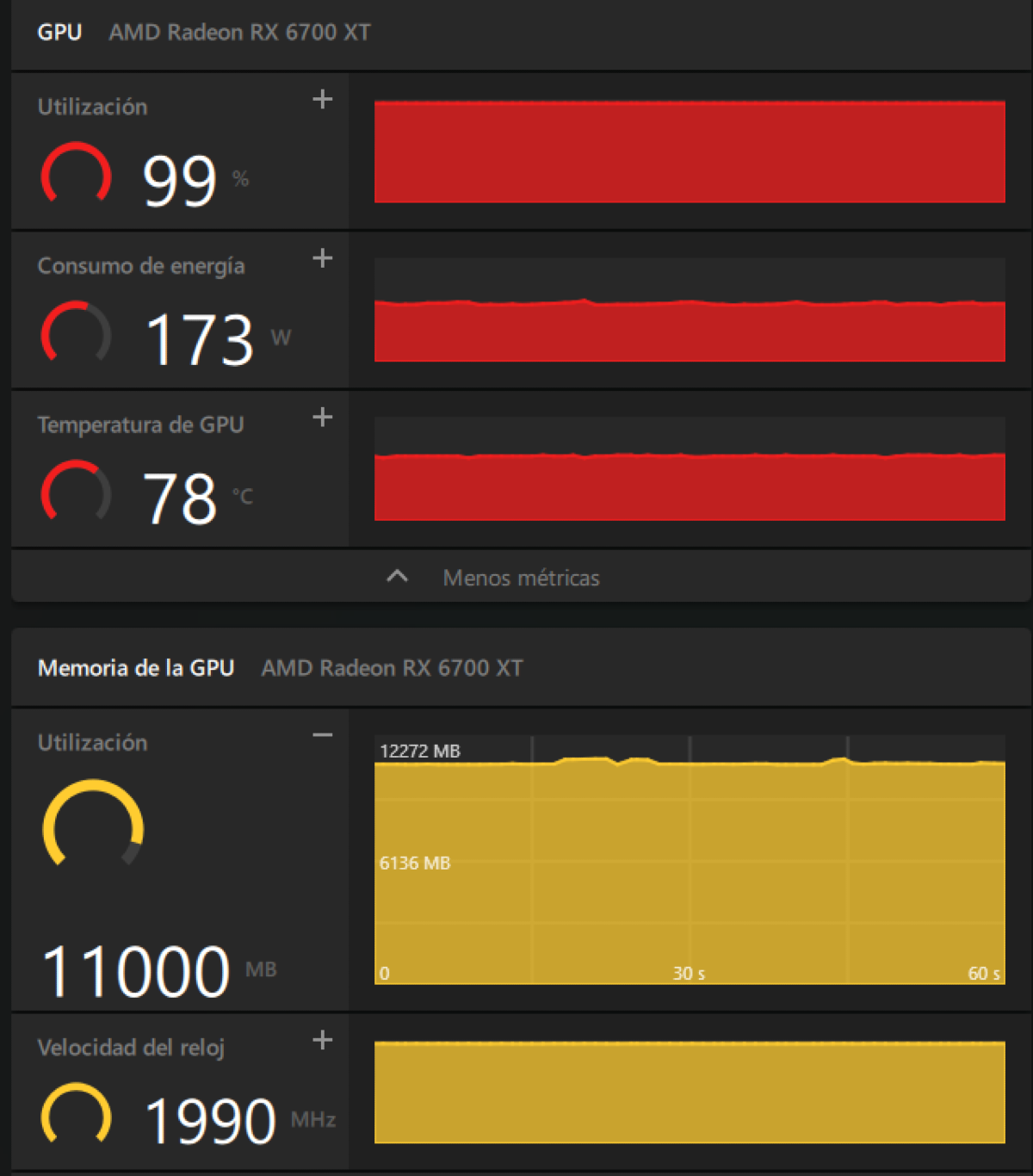
Hagamos de cuenta de que entiendo todo esto, no hace falta, pero por lo que pude sacar en mis breves indagaciones, ahí: -ngl 99 empuja todas las capas del modelo (los modelos tienen capas) a la VRAM; -c 40960 reserva 40k tokens de contexto; -fa on activa flash attention (una funcionalidad específica) y --cache-type-k q8_0 --cache-type-v q8_0cuantizan el KV cache: ese par de flags es lo que hace que 40k de contexto entren en 12 GB de VRAM con una RX 6700 XT. Lo importante es que esto alcanza para tener un modelo relativamente moderno, suficientemente grande y con suficiente ventana de contexto como para hacer lo que quiero. Recordemos, con una placa AMD no soportada y en Windows.
Captura de la VRAM de mi RX 6700 XT mientras corre Qwen 3 (Modelo) 8b (parámetros) en Q5_K_XL (cuantización) con 40k de contexto y KV cache en q8 (a esta altura ya es cuestión de creer). De los 12 GB de VRAM, el modelo más el cache se comen unos 9.
No quiero aburrir a nadie, y no hace falta que se instalen nada, quiero que se le pueda cazar la onda al proceso de hacer funcionar esto. Hasta acá tenemos llama.cpp con un modelo cargado en la VRAM. Así como está ya podrías hablarle al modelo a pelo. Simplemente tendrías que ir a tu navegador y poner http ://127.0.0.1:8080/ (sin espacio). Llama.cpp se ve algo así:
Dice que se llama Cristian, qué sé yo. Cabe destacar que al modelo (chino) le pregunté en castellano, "pensó" en inglés y respondió en castellano.
Si bien me ocupa la VRAM, sólo gasta electricidad mientras computa una respuesta. En ese caso durante 5.3 segundos. Ejecuta 54 tokens por segundo. Eso está bastante bien, es más o menos dos o tres veces la velocidad de lectura humana. Pero usarlo así como viene no me sirve, quiero usarlo para algo específico y que no me rompa nada. En el repositorio que acompaña a esta nota para los que quieran jugar con esto, si uno se lo baja y lo instala abriendo la carpeta (teniendo Python instalado) y poniendo pip install e ., debería quedar todo instalado. Esto registra los comandos obsidian-agent en su computadora y permite ejecutarlas (hay que abrir y cerrar la consola). Está todo listo, para convenciencia lo que queda es armar un atajo de teclado para poder llamar al modelo sin tipear nada, eso lo hago con PowerToys:
Ruta de acceso del programa: C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe, Argumentos: -NoExit -ExecutionPolicy Bypass -File C:\Users\Mauro\start-obsidian-agent.ps1. Ver la guía de inicio rápido en el repo.
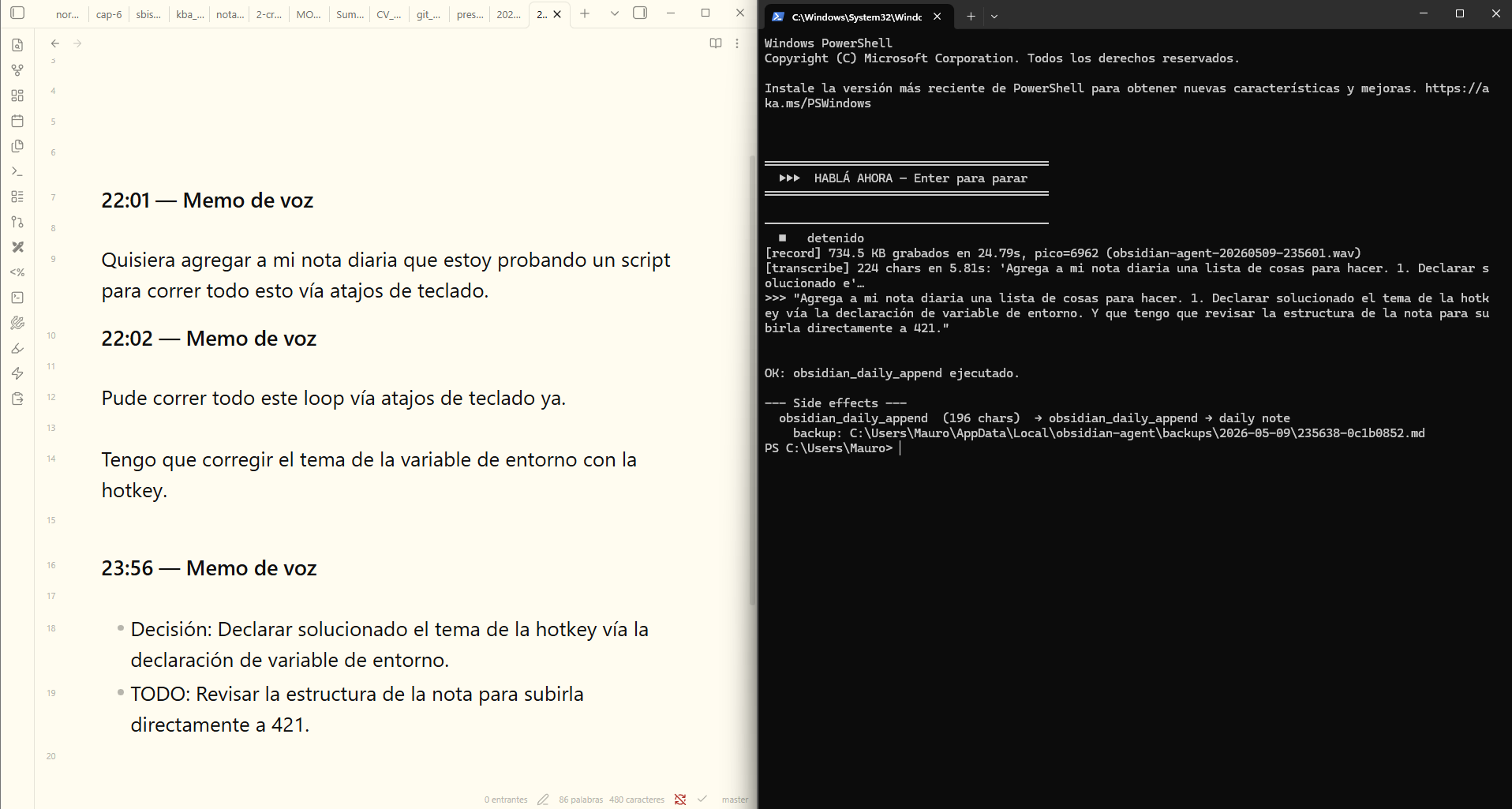
El flujo es así: estoy leyendo, se me ocurre algo, aprieto Ctrl+Shift+Q, digo en voz alta "anotá en mi nota diaria una lista de cosas que tengo que hacer: primero que tengo una reunión con un amigo, luego con un tesista, y a las 17:30 tengo que estar en la Facultad para dar una clase", le doy Enter, y unos segundos después esa idea quedó pegada al final de la nota diaria de hoy con el horario bien formateada como una lista. Si en cambio digo "buscame la última nota del vault y resumime el contenido", el agente arranca el loop: busca, lee la nota más fresca, y devuelve la síntesis en la consola. No es perfecto: whisper se confunde con nombres propios poco frecuentes y a veces el agente repite búsquedas antes de cortar. Pero como mecanismo para no perder la idea entre que la pensás y que llegás al teclado, funciona, y todo el cómputo pasó dentro de mi computadora.
El script abre una terminal, ejecuta un sonidito que me dice "hablá", describo lo que quiero y lo agrega a la nota diaria (una nota para anotaciones sueltas que está configurada en obsidian). Cuando termino de describir lo que quiero (simplemente hablando en el micrófono de mi computadora), aprieto Enter, termina la grabación, se lo pasa a whisper, luego al Qwen y el Qwen ejecuta los scripts del repo y agrega la info a mi nota.
No lo probé con este humilde proyecto, pero dejar corriendo un modelo en mi computadora de escritorio como server hogareño fácilmente permitiría que me conecte por LAN en mi casa, o incluso que por una conexión segura me conecte desde prácticamente cualquier lado a mi modelo local.
Qwen como interfaz en lenguaje natural de mi bóveda de Obsidian vía pi
Lo que sí probé es conectarle un harness, un programa que sirve de interfaz para transformar un modelo en asistente o agente (como Claude Code, Codex o Gemini CLI), más específicamente pi, también probé Hermes Agent, y existe OpenCode (que me recomendó Ramiro, un amigo que de esto sabe en serio). Usé pi porque no me da el cuero (todavía) para tener la ventana de contexto que necesita Hermes, que pide mínimo 60k, ni la versatilidad de OpenCode. Con un poquito de laburo configurando pi (buena parte del trabajo me lo hizo Claude), se ve así:
Pi.dev con el qwen3-8b cuantizado cargado en mi placa de video RX 6700 XT. Las fluctuaciones del visualizador (abajo izquierda) muestran cómo se va a ocupando la VRAM (luego de que se carga el modelo, arriba izquierda), y cómo gasta más electricidad y pone a trabajar mi placa cuando interactúo (lado derecho de la pantalla) con la consola de pi, ejecutada en el subsistema de Linux (WSL) de Windows.
Eso que se ve ahí es como un Claude Code local bastante peligroso porque es medio bobo. Pero si le agregás skills (tema para otro día) y/o le conectás un modelo más potente (como un Qwen de 30b, o un Gemma 4 de 27+), puede volverse bastante útil. En mi caso lo veo fácilmente como una especie de interfaz en lenguaje natural con mi vault de obsidian, le puedo pedir que acceda a mis archivos, que los resuma, que escriba nuevos, etc. El punto es que se puede.
Modelos locales hoy
Sí, podés correr modelos de lenguaje útiles en tu casa hoy, y la cosa va a mejorar. Si tenés una placa NVIDIA reciente, una Mac con buen chip M, o estás por comprar una notebook nueva con ciertas especificaciones, tenés casi todo lo que hace falta. Si no, podés empezar con modelos chicos e ir tomándole la mano al ecosistema (ollama, vllm, llama.cpp, whisper.cpp) mientras esperás que salga algún modelo de 30b que corra cómodo en 16 GB de VRAM, probablemente en pocos meses.
Lo importante no es que hoy puedas reemplazar a Claude Opus, ChatGPT 5.5 o Gemini 3.1 con una RTX 4070 (no podés, y por un buen rato no vas a poder). Lo importante es que para muchas tareas no hace falta un Opus, y la lista crece todos los meses. La pregunta deja de ser "¿es posible la privacidad con los LLMs?" (hay muchas opciones más sofisticadas, como esta que está trabajando Nico de PNYX, otro amigo, y consiste en anonimizar tus datos localmente con un modelo chico antes de pasarle el prompt a un modelo remoto) y pasan a ser: "¿qué tanto me interesa?", "¿cuánto cuesta?" y "¿vale la pena?". Estas son preguntas que también deberían hacerse las empresas, las universidades y el Estado antes de volverse dependientes de sistemas que se computan en la otra punta del planeta.
Filósofo. Docente en la UBA y doctorando CONICET (IIF-SADAF) a punto de defender su tesis sobre filosofía del lenguaje. Le interesa la relación entre normas y significado, además evalúa modelos de lenguaje.
Bancá el proyecto y desbloqueá todo: leé la Revista 421 un mes antes, comentá en cada nota, entrá al concilio mensual con la redacción y usá la app de Magic.